How LyricWinter Works: The Tech Behind AI Voice Stories
A dive into how LyricWinter works, from story parsing to AI voice cloning. Learn how we turn fanfiction and light-novels into immersive audio experiences.
Posted by
Related reading
Inworld TTS Steering Guide for LyricWinter
Use Inworld TTS 2 steering in LyricWinter with bracket cues, pause controls, acting direction, vocal reactions, and clean regeneration workflows.
Cartesia Emotion and SSML Controls in LyricWinter
How LyricWinter uses surrounding dialogue context with Cartesia Sonic 3.5, plus the full Cartesia emotion list and manual SSML controls.
Manual Emotion Tags with Chatterbox FAL in LyricWinter
Use Chatterbox FAL emotion tags in LyricWinter to add laughs, sighs, gasps, yawns, groans, coughs, chuckles, and sniffles to generated story audio.
I want to show you exactly how LyricWinter transforms your written stories into immersive audio experiences with distinct character voices. What started as a side project to fuel my desire to listen rather than read, has evolved into a sophisticated AI system that can handle hundreds of dialogue clips concurrently.
The Core Challenge: Multicharacter Voice Cloned Emotive Narration
The fundamental problem LyricWinter solves is simple to state but complex to execute: how do you take a written story with multiple characters and generate audio where each character has their own high quality, consistent voice associated with them?
Ideally we want all of the following qualities in our system:
- Multilingual
- Accurate cloning
- Excelling at nonlexical vocalizations
- Clear
- Emotive
- Fun to listen to over a long period
- Stable in long form
- Supporting multiple overlapping speakers
- Controllable
- Fast
- Affordable
We'll get into how to achieve all of these qualities in another article. First, let's understand how LyricWinter works.
Step 1: Understanding Your Story with AI
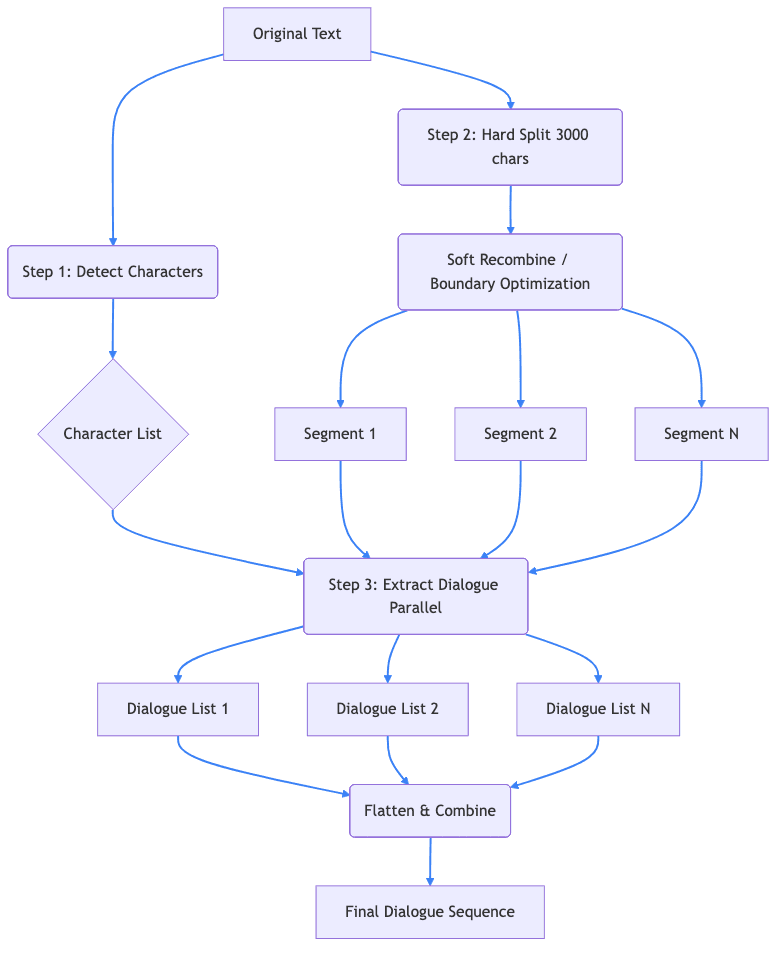
Figure 1: The recursive parsing and extraction pipeline
When you paste your story into LyricWinter, the first thing that happens is AI-powered story parsing.
Character Detection
The system uses AI to identify every unique character in your story. It's smart enough to recognize when "Harry", "Mr. Potter", and "The Boy Who Lived" all refer to the same character.
Dialogue Extraction & Attribution
Next comes: extracting dialogue. In order to narrate, we need to know what each speaking character is saying. LyricWinter uses AI alongside the character list from the previous step to extract the dialogue.
This is quite tricky, as dialogue attribution is not always obvious. Consider this challenging example which a user submitted for debugging:
While humans can do a decent job following the conversation flow, several lines lack explicit speaker tags. Who gave the "immediate" response? Who said "We won't"? Who muttered "So is doing nothing"?
Hermione and Ron are the most likely to say "Are you mad?" but since Ron later says "What if we get caught?" we can attribute the previous dialogue to him. Regarding the "So is doing nothing," we know it is said by a "he", so it could be either Ron or Harry, but given Harry's decisiveness, we can attribute it to him.
LyricWinter's AI analyzes conversation patterns, character personalities, and contextual clues to correctly parse this into individual dialogue clips:
[
{
"text": "We need to get this to Dumbledore,",
"speaker": "Harry"
},
{
"text": "Harry said urgently.",
"speaker": "Narrator"
},
{
"text": "Are you mad?",
"speaker": "Ron"
},
{
"text": "The response was immediate.",
"speaker": "Narrator"
},
{
"text": "It's past midnight.",
"speaker": "Ron"
},
{
"text": "Ron glanced nervously at the corridor.",
"speaker": "Narrator"
},
{
"text": "What if we get caught?",
"speaker": "Ron"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "he followed.",
"speaker": "Narrator"
},
{
"text": "Hermione had been quiet up till now.",
"speaker": "Narrator"
},
{
"text": "This is incredibly dangerous.",
"speaker": "Hermione"
},
{
"text": "So is doing nothing,",
"speaker": "Harry"
},
{
"text": "he muttered.",
"speaker": "Narrator"
},
{
"text": "Fine,",
"speaker": "Hermione"
},
{
"text": "she muttered.",
"speaker": "Narrator"
},
{
"text": "But if we end up in detention...",
"speaker": "Hermione"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "Harry repeated, already moving toward the portrait hole.",
"speaker": "Narrator"
}
]This step might take 1-2 minutes, or longer for longer stories. There are further optimizations that could be made to cut this down to ~10 seconds. i.e. finetuning an LLM on this task and running it on groq[7]. As LyricWinter gets more popular, I'll work on adding this.
Now then, each dialogue speaker pair is almost ready to be narrated.
Voice Assignment
Ok, we know that Harry said "We need to get this to Dumbledore," but... who is Harry? Harry is more than just a name. Harry is a character, with a personality, a voice, and a role in the story. In order to narrate immersively, we can't just assign a random voice to Harry. We need to assign a voice that is appropriate for Harry's personality and role in the story.
There are two scenarios:
- Some user has added a public voice for "Harry Potter" on My Voices
- No one has added a voice for "Harry Potter"
In the first scenario, AI is smart enough to associate "Harry Potter" the voice to "Harry" the character in the story.
In the second scenario, AI uses the name, description, and tags of each public voice to assign the most appropriate voice to "Harry". It will, for example, opt for a male british accented voice, if such a voice is available.
And of course privately set voices are also available only to you.
Here's what the AI suggested for our Harry Potter example:
{
"suggested_character_voices": {
"Ron": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "b4cddece-a29d-4652-94cf-1c0d80b4f380",
"voice_name": "Draco Malfoy"
},
"Harry": {
"model": "fishaudio",
"voice_id": "b03285ef-ade9-4785-aff1-ec07accc1735",
"voice_name": "Harry Potter"
},
"Hermione": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "1f9b9aef-41af-455c-822d-5dd0b4cc257e",
"voice_name": "Alice (Alice in Wonderland)"
},
"Narrator": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "5591864d-cfaf-490e-88e5-586e956847c3",
"voice_name": "Narrator"
},
"Dumbledore": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "76370ff9-1de1-48ab-9d64-a5b345584d1b",
"voice_name": "Zhongli"
}
}
}Notice how the AI found a "Harry Potter" voice match, but creatively assigned "Draco Malfoy" to Ron and "Alice" to Hermione based on voice characteristics and availability. Even Dumbledore gets paired with "Zhongli" - a wise, authoritative voice that fits the character. This is because no user has uploaded a Ron/Hermione/Dumbledore voice.
Also note the voice ids: There can be multiple voices with the same name, so voice ids are used to uniquely identify a voice during assignment.
Additionally, you can see the models that were suggested for each voice. Different AI labs release different models for voice cloning and text to speech, and these different models perform differently on different voices. The AI is not too good at suggesting models right now, so before you generate audio, you have the option to tweak the AI's suggestions, both the voice model and the voice itself.
Here's a breakdown of the voice models available in LyricWinter and their characteristics:
| Model | Quality | Character Accuracy | Reliability | Emotion |
|---|---|---|---|---|
inworld-2 | ||||
Fish Audio S2 Pro | ||||
inworld-1.5-max | ||||
cartesia-sonic-3.5 | ||||
chatterbox_fal | ||||
inworld-1.5-mini | ||||
zyphra | ||||
f5tts | ||||
misotts |
As you can see, each model has different strengths. gpt-4o-mini-tts+rvc excels at emotion and character accuracy, while tts-1+rvc offers the best quality and reliability. The AI tries to match the best model for each voice, but you have the final say in the generation process.
🌍 Multilingual Support by Model
English, Chinese, Japanese, German, French, Spanish, Korean, Arabic, Russian, Dutch, Italian, Polish, Portuguese
English, French, German, Japanese, Korean, Mandarin Chinese
English, Chinese
Note: fishaudio offers broad language support, making it ideal for international content and multilingual storytelling.
Step 2: Narrating Your Story with AI
Now that we have the dialogue and the voices selected, we can start narrating the story.
Narration
When you click Generate Audio, each Speaker, Dialogue, Text, Voice, and Voice Model combo is sent to the specified voice model to be synthesized. However, that's not enough. Context is crucial for emotionally immersive TTS. Take the following example:
Notice how Donald's first "I can't believe this is happening" should be voiced with devastation and tears ("his shoulders shaking with sobs"), while his later dialogue should sound cold and angry ("his eyes blazing with anger"). Without the surrounding context, a TTS system might generate both lines with the same emotional tone, missing the dramatic arc of the conversation.
LyricWinter's AI analyzes the emotional context surrounding each line to guide the voice model's emotional expression. Here's which models support emotional steering:
Models WITH Expressive or Contextual Control:
- Zyphra ZONOS2[3]: Uses Zyphra Cloud cloned voices with expressive generation enabled. The Cloud API does not expose the old Zonos v0.1 per-emotion weight controls, so LyricWinter treats it as expressive synthesis rather than slider-based emotion control. One shot voice cloning.
- Cartesia Sonic 3.5[10][11]: LyricWinter analyzes surrounding dialogue context and maps it into Cartesia's native
generation_configcontrols for emotion, speed, and volume when useful. If a line already contains Cartesia SSML controls such as<emotion value="sad"/>, LyricWinter preserves the user-authored control and skips automatic Cartesia guidance for that clip. One shot voice cloning. - gpt-4o-mini-tts[1]: Employs contextual instructions based on story analysis. The system examines surrounding dialogue and narrative to generate natural language instructions that guide emotional delivery. Training based voice cloning.
Models WITH Manual Inline Emotion Tags:
- Fish Audio[2]: Supports manual S2-style square-bracket tags such as
[whispering],[excited], and[laughing]when those cues are written into the line text. - Chatterbox FAL[9]: Supports manual angle-bracket sound tags inside text:
<laugh>,<chuckle>,<sigh>,<cough>,<sniffle>,<groan>,<yawn>, and<gasp>. LyricWinter keeps Chatterbox's seed stable per speaker during the initial audio run, then uses action-specific retry salts for clip and speaker regenerations so retries can produce a new take.
Models WITHOUT LyricWinter Emotion Controls:
- tts-1+rvc[1][4]: Training based voice cloning
- sparktts [Deprecated][8]: One shot voice cloning. While the underlying technology supports 24 emotion categories, LyricWinter's current implementation doesn't use contextual emotion analysis.
That's not to say tts-1 or fishaudio are bad by any means because they don't get context-dependent emotional steering, they are great. There are tradeoffs to be made. I myself prefer tts-1 for the Narrator for the cadence consistency.
Error Handling
What do you do when the voice model messes up? Some models can cut out syllables near the start or end of the line. We use whisper[5] to transcribe the audio and check if the generation was successful. If not, we try again a few times. If it continues to fail, we fall back to a different voice model. That's the core -- try again, and fallback if needed.
Retries slow things down, but ultimately we want high quality results. Usually it's not too bad, and newer provider APIs can still vary by voice, prompt length, and input sample quality. We keep provider fallbacks available so a single model failure does not block a story.
And of course, error tracking! Errors are logged for review.
Speed
Some of these models run on external services, some run on serverless infrastructure. Nonetheless requests are distributed for speed! Shoutout to Modal[6]. Originally I used Runpod and Google Cloud Run, but --- they were too slow. + Modal gave me a bunch of free credits. I love them. When each request completes, the client (your browser) pulls in the audio and concatenates it. As soon as the first dialogue clip is complete, you can start listening!
Time to listen!
Your audio is ready to listen to, and you can optionally download as a .wav or download the .srt file as desired.
Try It Yourself!
The best way to understand LyricWinter is to experience it. Head over to the Generate page, paste in your favorite fanfiction, light novel, or short story, and watch as AI brings your favorite characters into the audio domain with immersion. We have a generous English-supported free tier with SparkTTS [Deprecated], so you can experiment without any commitment.
Whether you're a fanfiction writer wanting to hear your stories aloud, a light novel reader looking for narration tools, or just curious about AI voice technology, LyricWinter offers something unique: the ability to transform any text into an immersive audio experience with distinct character voices, all in just a few clicks.
Happy story telling! And if you have any questions or feedback, feel free to reach out. I'm always excited to hear how people are using LyricWinter and what features they'd like to see next.
Note
Impersonation or nefarious use is not allowed! This is for recreation and personal use. LyricWinter is not affiliated with, nor does it claim ownership of, any user-uploaded voices. As highlighted in this article, LyricWinter is input and voice agnostic system. Examples given are for illustration purposes only.
References
- [1]OpenAI Platform - Text-to-Speech Guide
- [2]Fish Audio - Text-to-Speech Platform
- [3]Zyphra Cloud - ZONOS2 Speech API
- [4]RVC-Project - Retrieval-based Voice Conversion WebUI
- [5]OpenAI Whisper - Automatic Speech Recognition
- [6]Modal - Serverless GPU Computing Platform
- [7]Groq - Fast AI Inference Platform
- [8]SparkAudio - Spark TTS
- [9]fal.ai - Chatterbox Text to Speech API
- [10]Cartesia - Volume, Speed, Emotion
- [11]Cartesia - SSML Tags