Como o LyricWinter funciona: a tecnologia por trás das histórias com vozes de IA
Um mergulho em como o LyricWinter funciona, da análise de histórias à clonagem de voz com IA. Veja como transformamos fanfiction e light novels em experiências de áudio imersivas.
Publicado por
Leitura relacionada
Como as vozes fixadas funcionam no LyricWinter
Aprenda como as vozes fixadas do LyricWinter salvam atribuições de personagens, lidam com aliases e reutilizam prévias de Voz de IA entre histórias.
Importe histórias do AO3 e FanFiction.net para o LyricWinter
Importe histórias do AO3 ou FanFiction.net para o LyricWinter, gere links compartilháveis e transforme fanfiction em áudio com vozes de IA de múltiplos personagens.
Como ouvir fanfiction (grátis, rápido e com várias vozes)
Aprenda as formas mais fáceis de ouvir fanfiction: TTS gratuito e rápido, leitura em voz alta do navegador, podfics da comunidade e a opção mais imersiva: áudio de IA com múltiplos personagens no LyricWinter. Passo a passo incluído.
Quero mostrar exatamente como o LyricWinter transforma suas histórias escritas em experiências de áudio imersivas com vozes de personagens distintas. O que começou como um projeto paralelo para alimentar meu desejo de ouvir em vez de ler, evoluiu para um sistema de IA sofisticado que pode lidar com centenas de clipes de diálogo simultaneamente.
O Desafio Central: Narração Emotiva Clonada de Voz de Múltiplos Personagens
O problema fundamental que o LyricWinter resolve é simples de enunciar, mas complexo de executar: como pegar uma história escrita com vários personagens e gerar áudio onde cada personagem tem sua própria voz consistente e de alta qualidade associada a ele?
Idealmente, queremos todas as seguintes qualidades em nosso sistema:
- Multilíngue
- Clonagem precisa
- Excelente em vocalizações não lexicais
- Limpar
- Emotivo
- Divertido de ouvir por um longo período
- Estável em formato longo
- Suporte a múltiplos locutores sobrepostos
- Controlável
- Rápido
- Acessível
Vamos entrar em como alcançar todas essas qualidades em outro artigo. Primeiro, vamos entender como LyricWinter funciona.
Step 1: Understanding Your Story with AI
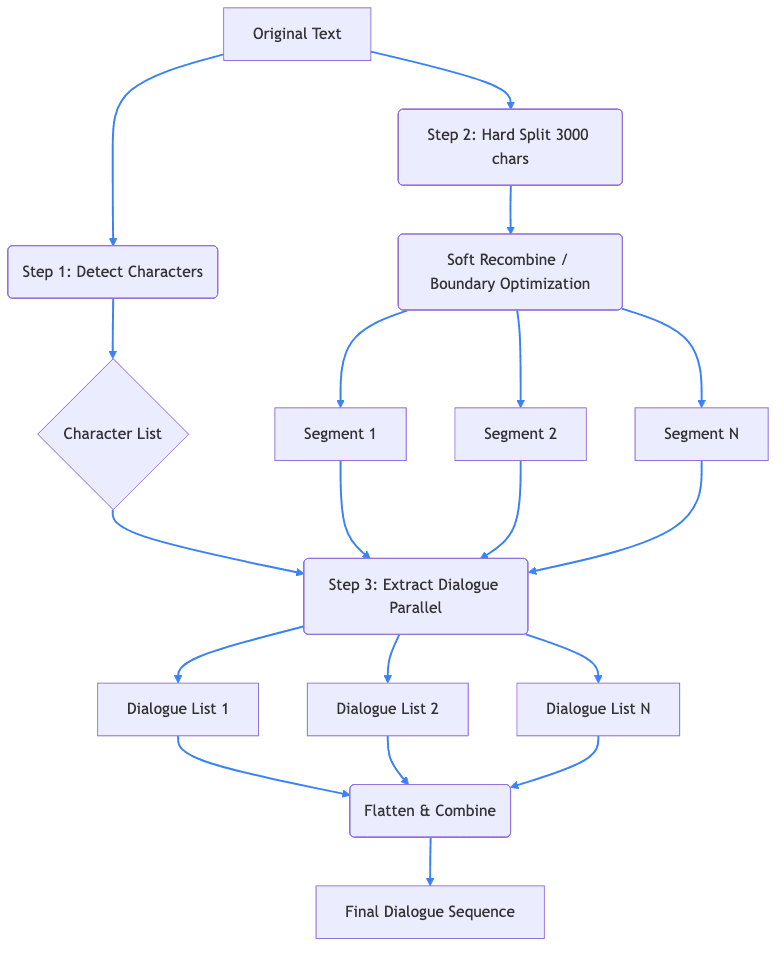
Figure 1: The recursive parsing and extraction pipeline
Quando você cola sua história no LyricWinter, a primeira coisa que acontece é a análise da história com tecnologia de IA.
Detecção de Personagem
O sistema usa IA para identificar cada personagem único em sua história. É inteligente o suficiente para reconhecer quando "Harry", "Mr. Potter" e "The Boy Who Lived" se referem ao mesmo personagem.
Extração e Atribuição de Diálogo
Em seguida, vem: extrair o diálogo. Para narrar, precisamos saber o que cada personagem está dizendo. LyricWinter usa IA junto com a lista de personagens da etapa anterior para extrair o diálogo.
Isso é bastante complicado, pois a atribuição de diálogo nem sempre é óbvia. Considere este exemplo desafiador que um usuário enviou para depuração:
Embora humanos possam fazer um trabalho razoável seguindo o fluxo da conversa, várias linhas carecem de tags de locutor explícitas. Quem deu a resposta "imediata"? Quem disse "Nós não vamos"? Quem murmurou "O mesmo vale para não fazer nada"?
Hermione e Ron são os mais propensos a dizer "Você está louco?", mas como Ron mais tarde diz "E se formos pegos?", podemos atribuir o diálogo anterior a ele. Em relação a "Então, não fazer nada também", sabemos que é dito por um "ele", então poderia ser Ron ou Harry, mas dada a decisão de Harry, podemos atribuí-lo a ele.
A IA do LyricWinter analisa padrões de conversação, personalidades de personagens e pistas contextuais para analisar corretamente isso em clipes de diálogo individuais:
[
{
"text": "We need to get this to Dumbledore,",
"speaker": "Harry"
},
{
"text": "Harry said urgently.",
"speaker": "Narrator"
},
{
"text": "Are you mad?",
"speaker": "Ron"
},
{
"text": "The response was immediate.",
"speaker": "Narrator"
},
{
"text": "It's past midnight.",
"speaker": "Ron"
},
{
"text": "Ron glanced nervously at the corridor.",
"speaker": "Narrator"
},
{
"text": "What if we get caught?",
"speaker": "Ron"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "he followed.",
"speaker": "Narrator"
},
{
"text": "Hermione had been quiet up till now.",
"speaker": "Narrator"
},
{
"text": "This is incredibly dangerous.",
"speaker": "Hermione"
},
{
"text": "So is doing nothing,",
"speaker": "Harry"
},
{
"text": "he muttered.",
"speaker": "Narrator"
},
{
"text": "Fine,",
"speaker": "Hermione"
},
{
"text": "she muttered.",
"speaker": "Narrator"
},
{
"text": "But if we end up in detention...",
"speaker": "Hermione"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "Harry repeated, already moving toward the portrait hole.",
"speaker": "Narrator"
}
]Esta etapa pode levar de 1 a 2 minutos, ou mais para histórias mais longas. Existem outras otimizações que poderiam ser feitas para reduzir isso para ~10 segundos. i.e. ajustar um LLM nesta tarefa e executá-lo no groq[7]. À medida que o LyricWinter se torna mais popular, trabalharei para adicionar isso.
Agora, cada par de falantes de diálogo está quase pronto para ser narrado.
Voice Assignment
Ok, sabemos que Harry disse "Precisamos levar isso para Dumbledore", mas... quem é Harry? Harry é mais do que apenas um nome. Harry é um personagem, com uma personalidade, uma voz e um papel na história. Para narrar de forma imersiva, não podemos simplesmente atribuir uma voz aleatória a Harry. Precisamos atribuir uma voz que seja apropriada para a personalidade e o papel de Harry na história.
Existem dois cenários:
- Alguns usuários adicionaram uma voz pública para "Harry Potter" em Minhas Vozes
- Ninguém adicionou uma voz para "Harry Potter"
No primeiro cenário, a IA é inteligente o suficiente para associar a voz de "Harry Potter" ao personagem "Harry" na história.
No segundo cenário, a IA usa o nome, a descrição e as tags de cada voz pública para atribuir a voz mais apropriada a "Harry". Irá, por exemplo, optar por uma voz masculina com sotaque britânico, se tal voz estiver disponível.
E, claro, as vozes definidas de forma privada também estão disponíveis apenas para você.
Aqui está o que a IA sugeriu para o nosso exemplo de Harry Potter:
{
"suggested_character_voices": {
"Ron": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "b4cddece-a29d-4652-94cf-1c0d80b4f380",
"voice_name": "Draco Malfoy"
},
"Harry": {
"model": "fishaudio",
"voice_id": "b03285ef-ade9-4785-aff1-ec07accc1735",
"voice_name": "Harry Potter"
},
"Hermione": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "1f9b9aef-41af-455c-822d-5dd0b4cc257e",
"voice_name": "Alice (Alice in Wonderland)"
},
"Narrator": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "5591864d-cfaf-490e-88e5-586e956847c3",
"voice_name": "Narrator"
},
"Dumbledore": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "76370ff9-1de1-48ab-9d64-a5b345584d1b",
"voice_name": "Zhongli"
}
}
}Observe como a IA encontrou uma correspondência de voz para "Harry Potter", mas atribuiu criativamente "Draco Malfoy" a Ron e "Alice" a Hermione com base nas características e disponibilidade da voz. Até mesmo Dumbledore é emparelhado com "Zhongli" - uma voz sábia e autoritária que se encaixa no personagem. Isso ocorre porque nenhum usuário carregou uma voz de Ron/Hermione/Dumbledore.
Observe também os ids de voz: pode haver várias vozes com o mesmo nome, portanto, os ids de voz são usados para identificar exclusivamente uma voz durante a atribuição.
Além disso, você pode ver os modelos que foram sugeridos para cada voz. Diferentes laboratórios de IA lançam diferentes modelos para clonagem de voz e texto para fala, e esses diferentes modelos têm desempenhos diferentes em diferentes vozes. A IA não é muito boa em sugerir modelos agora, então, antes de gerar áudio, você tem a opção de ajustar as sugestões da IA, tanto o modelo de voz quanto a própria voz.
Aqui está uma análise dos modelos de voz disponíveis no LyricWinter e suas características:
| Modelo | Qualidade | Precisão do personagem | Confiabilidade | Emoção |
|---|---|---|---|---|
fishaudio | ||||
sparktts [OBSOLETO] | ||||
zyphra [OBSOLETO] |
Como pode ver, cada modelo tem diferentes pontos fortes. gpt-4o-mini-tts+rvc destaca-se na emoção e na precisão do personagem, enquanto tts-1+rvc oferece a melhor qualidade e fiabilidade. A IA tenta corresponder ao melhor modelo para cada voz, mas tem a palavra final no processo de geração.
🌍 Suporte multilíngue por modelo
Inglês, chinês, japonês, alemão, francês, espanhol, coreano, árabe, russo, holandês, italiano, polonês, português
Inglês, francês, alemão, japonês, coreano, chinês mandarim
Inglês, chinês
Observação: fishaudio oferece amplo suporte a idiomas, o que o torna ideal para conteúdo internacional e histórias multilíngues.
Passo 2: Narrando Sua História com IA
Agora que temos o diálogo e as vozes selecionadas, podemos começar a narrar a história.
Narração
Quando você clica em Gerar Áudio, cada combinação de Locutor, Diálogo, Texto, Voz e Modelo de Voz é enviada ao modelo de voz especificado para ser sintetizada. No entanto, isso não é suficiente. O contexto é crucial para um TTS emocionalmente imersivo. Veja o exemplo a seguir:
Observe como o primeiro "Eu não acredito que isso está acontecendo" de Donald deve ser dublado com devastação e lágrimas ("seus ombros tremendo com soluços"), enquanto seu diálogo posterior deve soar frio e zangado ("seus olhos brilhando de raiva"). Sem o contexto circundante, um sistema de TTS pode gerar ambas as falas com o mesmo tom emocional, perdendo o arco dramático da conversa.
A IA do LyricWinter analisa o contexto emocional em torno de cada linha para orientar a expressão emocional do modelo de voz. Aqui estão quais modelos suportam direção emocional:
Models WITH Emotional Control:
- zyphra zonos-v0.1 [Deprecated][3]: Usa pesos emocionais de 8 dimensões, incluindo felicidade, tristeza, raiva, medo, surpresa, nojo, neutro e outros. A IA analisa o contexto da história para definir automaticamente os níveis de emoção apropriados para cada linha de diálogo. Clonagem de voz one-shot.
- gpt-4o-mini-tts[1]: Emprega instruções contextuais baseadas na análise da história. O sistema examina o diálogo e a narrativa circundantes para gerar instruções em linguagem natural que orientam a entrega emocional. Clonagem de voz baseada em treinamento.
Models WITHOUT Emotional Control:
- tts-1+rvc[1][4]: Clonagem de voz baseada em treinamento
- fishaudio[2]: Clonagem de voz one-shot
- sparktts [Deprecated][8]: Clonagem de voz one-shot. Embora a tecnologia subjacente suporte 24 categorias de emoção, a implementação atual do LyricWinter não usa análise de emoção contextual.
Isso não quer dizer que tts-1 ou fishaudio sejam ruins de forma alguma porque eles não obtêm direção emocional dependente do contexto, eles são ótimos. Há compensações a serem feitas. Eu mesmo prefiro tts-1 para o Narrador pela consistência da cadência.
Tratamento de Erros
O que você faz quando o modelo de voz falha? Zyphra zonos-v0.1 [Deprecated], por exemplo, frequentemente corta sílabas perto do início ou do fim da linha. Usamos whisper[5] para transcrever o áudio e verificar se a geração foi bem-sucedida. Caso contrário, tentamos novamente algumas vezes. Se continuar falhando, recorremos a um modelo de voz diferente. Esse é o núcleo: tentar novamente e, se necessário, usar um fallback.
As tentativas repetidas tornam as coisas mais lentas, mas, em última análise, queremos resultados de alta qualidade. Normalmente, não é tão ruim. Embora o zonos [Deprecated] seja bastante não confiável. Eu realmente fiz uma entrevista com eles -- um salve para eles! Eles construíram um bom produto, embora eles totalmente deveriam ter me contratado para tornar as coisas confiáveis.
E, claro, rastreamento de erros! Os erros são registrados para revisão.
Velocidade
Alguns desses modelos são executados em serviços externos, outros em infraestrutura serverless. No entanto, as solicitações são distribuídas para maior velocidade! Um agradecimento especial ao Modal[6]. Originalmente, eu usava Runpod e Google Cloud Run, mas --- eles eram muito lentos. + O Modal me deu vários créditos gratuitos. Eu os adoro. Quando cada solicitação é concluída, o cliente (seu navegador) puxa o áudio e o concatena. Assim que o primeiro clipe de diálogo é concluído, você pode começar a ouvir!
Hora de ouvir!
Seu áudio está pronto para ser ouvido e você pode, opcionalmente, baixar como um arquivo .wav ou baixar o arquivo .srt, conforme desejado.
Experimente Você Mesmo!
A melhor maneira de entender o LyricWinter é experimentá-lo. Vá para a página de Geração, cole sua fanfiction, light novel ou conto favorito e veja como a IA traz seus personagens favoritos para o domínio do áudio com imersão. Temos um generoso nível gratuito com suporte em inglês com SparkTTS [Deprecated], para que você possa experimentar sem nenhum compromisso.
Seja você um escritor de fanfiction querendo ouvir suas histórias em voz alta, um leitor de light novels procurando ferramentas de narração ou apenas curioso sobre a tecnologia de voz de IA, LyricWinter oferece algo único: a capacidade de transformar qualquer texto em uma experiência de áudio imersiva com vozes de personagens distintas, tudo em apenas alguns cliques.
Feliz narração de histórias! E se você tiver alguma dúvida ou feedback, sinta-se à vontade para entrar em contato. Estou sempre animado para saber como as pessoas estão usando o LyricWinter e quais recursos gostariam de ver em seguida.
Nota
Impersonificação ou uso nefasto não são permitidos! Isto é para recreação e uso pessoal. LyricWinter não é afiliado, nem reivindica a propriedade de nenhuma voz enviada pelo usuário. Como destacado neste artigo, LyricWinter é um sistema agnóstico de entrada e voz. Os exemplos fornecidos são apenas para fins ilustrativos.
References
- [1]OpenAI Platform - Text-to-Speech Guide
- [2]Fish Audio - Text-to-Speech Platform
- [3]Zyphra - Zonos v0.1
- [4]RVC-Project - Retrieval-based Voice Conversion WebUI
- [5]OpenAI Whisper - Automatic Speech Recognition
- [6]Modal - Serverless GPU Computing Platform
- [7]Groq - Fast AI Inference Platform
- [8]SparkAudio - Spark TTS