So funktioniert LyricWinter: Die Technik hinter KI-Hörgeschichten
Ein Blick darauf, wie LyricWinter funktioniert - von der Story-Analyse bis zum KI-Voice-Cloning. Erfahre, wie wir Fanfiction und Light Novels in immersive Audioerlebnisse verwandeln.
Veröffentlicht von
Weiterführende Lektüre
So funktionieren Pinned Voices in LyricWinter
Erfahre, wie Pinned Voices in LyricWinter Charakterzuweisungen speichern, Aliase verarbeiten und AI Voice-Vorschauen über mehrere Storys hinweg wiederverwenden.
AO3- und FanFiction.net-Storys in LyricWinter importieren
Importiere AO3- oder FanFiction.net-Storys in LyricWinter, generiere teilbare Links und verwandle Fanfiction in KI-Audio mit mehreren Charakterstimmen.
Fanfiction hören: kostenlos, schnell und mit mehreren Stimmen
Lerne die einfachsten Möglichkeiten kennen, Fanfiction zu hören: schnelles kostenloses TTS, Browser-Read-Aloud, Community-Podfics und die immersivste Option: KI-Audio mit mehreren Charakterstimmen durch LyricWinter. Schritt-für-Schritt-Anleitung enthalten.
Ich möchte Ihnen genau zeigen, wie LyricWinter Ihre geschriebenen Geschichten in immersive Audioerlebnisse mit eindeutigen Charakterstimmen verwandelt. Was als Nebenprojekt begann, um meine Lust am Zuhören statt am Lesen zu wecken, hat sich zu einem hochentwickelten KI-System entwickelt, das Hunderte von Dialogclips gleichzeitig verarbeiten kann.
Die zentrale Herausforderung: Emotionale Erzählung mit geklonter Stimme aus mehreren Zeichen
Das grundlegende Problem, das LyricWinter löst, ist einfach zu formulieren, aber komplex in der Umsetzung: Wie kann man aus einer geschriebenen Geschichte mit mehreren Charakteren Audio erzeugen, bei dem jedem Charakter seine eigene hochwertige, konsistente Stimme zugeordnet ist?
Idealerweise möchten wir alle der folgenden Eigenschaften in unserem System haben:
- Mehrsprachig
- Präzises Klonen
- Hervorragend bei nichtlexikalischen Lautäußerungen
- Klar
- Emotional
- Macht Spaß, über einen längeren Zeitraum zuzuhören
- Stabil in Langform
- Unterstützt mehrere überlappende Lautsprecher
- Kontrollierbar
- Schnell
- Erschwinglich
Wie Sie all diese Eigenschaften erreichen, erfahren Sie in einem anderen Artikel. Lassen Sie uns zunächst verstehen, wie LyricWinter funktioniert.
Step 1: Understanding Your Story with AI
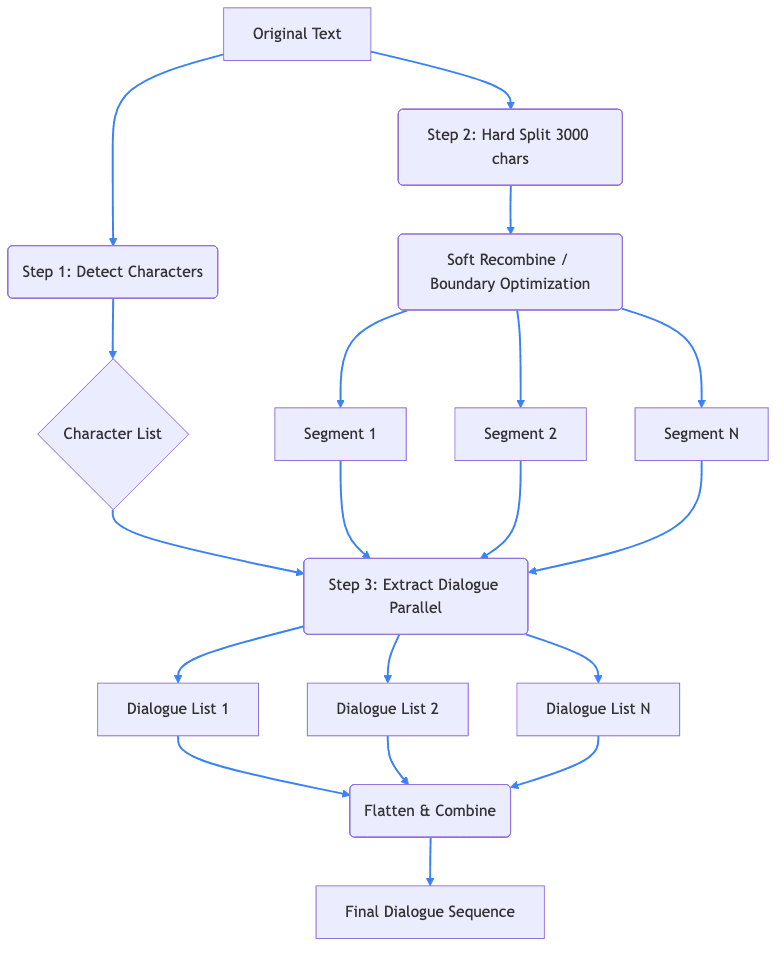
Figure 1: The recursive parsing and extraction pipeline
Wenn Sie Ihre Story in LyricWinter einfügen, geschieht als Erstes die von AI unterstützte Story-Analyse.
Zeichenerkennung
Das System verwendet KI, um jeden einzelnen Charakter in Ihrer Geschichte zu identifizieren. Es ist intelligent genug, um zu erkennen, wann sich „Harry“, „Mr. Potter“und „Der Junge, der lebte“auf denselben Charakter beziehen.
Dialogextraktion und Attribution
Als nächstes kommt: Dialog extrahieren. Um zu erzählen, müssen wir wissen, was jeder sprechende Charakter sagt. LyricWinter verwendet KI zusätzlich zur Charakterliste aus dem vorherigen Schritt, um den Dialog zu extrahieren.
Dies ist ziemlich schwierig, da die Zuordnung von Dialogen nicht immer offensichtlich ist. Betrachten Sie dieses herausfordernde Beispiel, das ein Benutzer zum Debuggen eingereicht hat:
Während Menschen dem Gesprächsfluss gut folgen können, fehlen in einigen Zeilen explizite Sprecher-Tags. Wer hat die „sofortige“Antwort gegeben? Wer hat gesagt: „Das werden wir nicht“? Wer hat gemurmelt: „Also nichts tun“?
Hermine und Ron fragen am ehesten: „Bist du verrückt?“aber da Ron später sagt: „Was ist, wenn wir erwischt werden?“wir können ihm den vorherigen Dialog zuschreiben. Was das „So ist nichts tun“betrifft, wissen wir, dass es von einem „er“gesagt wird, also könnte es entweder Ron oder Harry sein, aber angesichts von Harrys Entschlossenheit können wir es ihm zuschreiben.
Die KI von LyricWinter analysiert Gesprächsmuster, Charakterpersönlichkeiten und kontextbezogene Hinweise, um diese korrekt in einzelne Dialogclips zu analysieren:
[
{
"text": "We need to get this to Dumbledore,",
"speaker": "Harry"
},
{
"text": "Harry said urgently.",
"speaker": "Narrator"
},
{
"text": "Are you mad?",
"speaker": "Ron"
},
{
"text": "The response was immediate.",
"speaker": "Narrator"
},
{
"text": "It's past midnight.",
"speaker": "Ron"
},
{
"text": "Ron glanced nervously at the corridor.",
"speaker": "Narrator"
},
{
"text": "What if we get caught?",
"speaker": "Ron"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "he followed.",
"speaker": "Narrator"
},
{
"text": "Hermione had been quiet up till now.",
"speaker": "Narrator"
},
{
"text": "This is incredibly dangerous.",
"speaker": "Hermione"
},
{
"text": "So is doing nothing,",
"speaker": "Harry"
},
{
"text": "he muttered.",
"speaker": "Narrator"
},
{
"text": "Fine,",
"speaker": "Hermione"
},
{
"text": "she muttered.",
"speaker": "Narrator"
},
{
"text": "But if we end up in detention...",
"speaker": "Hermione"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "Harry repeated, already moving toward the portrait hole.",
"speaker": "Narrator"
}
]Dieser Schritt kann 1–2 Minuten dauern, bei längeren Geschichten auch länger. Es könnten weitere Optimierungen vorgenommen werden, um diese Zeit auf etwa 10 Sekunden zu reduzieren. d. h. die Feinabstimmung eines LLM für diese Aufgabe und die Ausführung auf groq[7]. Da LyricWinter immer beliebter wird, werde ich daran arbeiten, dies hinzuzufügen.
Nun ist jedes Sprecherpaar des Dialogs fast bereit, erzählt zu werden.
Voice Assignment
Ok, wir wissen, dass Harry sagte: „Wir müssen das zu Dumbledore bringen“, aber... wer ist Harry? Harry ist mehr als nur ein Name. Harry ist eine Figur mit einer Persönlichkeit, einer Stimme und einer Rolle in der Geschichte. Um eine immersive Geschichte zu erzählen, können wir Harry nicht einfach eine zufällige Stimme zuweisen. Wir müssen eine Stimme zuweisen, die zu Harrys Persönlichkeit und seiner Rolle in der Geschichte passt.
Es gibt zwei Szenarien:
- Einige Benutzer haben eine öffentliche Stimme für „Harry Potter“auf My Voices hinzugefügt
- Niemand hat eine Stimme für „Harry Potter“hinzugefügt
Im ersten Szenario ist die KI intelligent genug, um „Harry Potter“, die Stimme, mit „Harry“, der Figur in der Geschichte, zu verknüpfen.
Im zweiten Szenario verwendet die KI den Namen, die Beschreibung und die Tags jeder öffentlichen Stimme, um „Harry“die am besten geeignete Stimme zuzuweisen. Es wird sich beispielsweise für eine männliche Stimme mit britischem Akzent entscheiden, sofern eine solche Stimme verfügbar ist.
Und natürlich stehen auch privat eingestellte Stimmen nur Ihnen zur Verfügung.
Folgendes hat die KI für unser Harry-Potter-Beispiel vorgeschlagen:
{
"suggested_character_voices": {
"Ron": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "b4cddece-a29d-4652-94cf-1c0d80b4f380",
"voice_name": "Draco Malfoy"
},
"Harry": {
"model": "fishaudio",
"voice_id": "b03285ef-ade9-4785-aff1-ec07accc1735",
"voice_name": "Harry Potter"
},
"Hermione": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "1f9b9aef-41af-455c-822d-5dd0b4cc257e",
"voice_name": "Alice (Alice in Wonderland)"
},
"Narrator": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "5591864d-cfaf-490e-88e5-586e956847c3",
"voice_name": "Narrator"
},
"Dumbledore": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "76370ff9-1de1-48ab-9d64-a5b345584d1b",
"voice_name": "Zhongli"
}
}
}Beachten Sie, wie die KI eine „Harry Potter“-Stimme gefunden hat, diese aber aufgrund der Stimmeigenschaften und der Verfügbarkeit kreativ „Draco Malfoy“Ron und „Alice“Hermine zuordnete. Sogar Dumbledore wird mit „Zhongli“zusammengebracht – einer weisen, maßgeblichen Stimme, die zum Charakter passt. Dies liegt daran, dass kein Benutzer eine Ron/Hermione/Dumbledore-Stimme hochgeladen hat.
Beachten Sie auch die Stimmen-IDs: Es kann mehrere Stimmen mit demselben Namen geben, daher werden Stimmen-IDs verwendet, um eine Stimme bei der Zuweisung eindeutig zu identifizieren.
Darüber hinaus können Sie die Modelle sehen, die für jede Stimme vorgeschlagen wurden. Verschiedene KI-Labore veröffentlichen unterschiedliche Modelle für das Klonen von Stimmen und Text-to-Speech, und diese unterschiedlichen Modelle funktionieren bei unterschiedlichen Stimmen unterschiedlich. Die KI ist derzeit nicht besonders gut darin, Modelle vorzuschlagen. Bevor Sie also Audio erzeugen, haben Sie die Möglichkeit, die Vorschläge der KI zu optimieren, sowohl das Sprachmodell als auch die Stimme selbst.
Hier ist eine Aufschlüsselung der in LyricWinter verfügbaren Sprachmodelle und ihrer Eigenschaften:
| Modell | Qualität | Figuren treue | Zuverlässigkeit | Emotion |
|---|---|---|---|---|
fishaudio | ||||
sparktts [VERALTET] | ||||
zyphra [VERALTET] |
Wie Sie sehen, hat jedes Modell unterschiedliche Stärken. gpt-4o-mini-tts+rvc zeichnet sich durch Emotion und Charaktergenauigkeit aus, während tts-1+rvc die beste Qualität und Zuverlässigkeit bietet. Die KI versucht, für jede Stimme das beste Modell zu finden, aber Sie haben das letzte Wort beim Generierungsprozess.
🌍 Mehrsprachige Unterstützung nach Modell
Englisch, Chinesisch, Japanisch, Deutsch, Französisch, Spanisch, Koreanisch, Arabisch, Russisch, Niederländisch, Italienisch, Polnisch, Portugiesisch
Englisch, Französisch, Deutsch, Japanisch, Koreanisch, Mandarin-Chinesisch
Englisch, Chinesisch
Hinweis: fishaudio bietet breite Sprachunterstützung und ist damit ideal für internationale Inhalte und mehrsprachiges Storytelling.
Schritt 2: Erzählen Sie Ihre Geschichte mit KI
Nachdem wir nun den Dialog und die Stimmen ausgewählt haben, können wir mit dem Erzählen der Geschichte beginnen.
Erzählung
Wenn Sie auf Generate Audio klicken, wird jede Kombination aus Lautsprecher, Dialog, Text, Stimme und Sprachmodell zur Synthese an das angegebene Sprachmodell gesendet. Das reicht jedoch nicht aus. Der Kontext ist entscheidend für ein emotional immersives TTS. Nehmen Sie das folgende Beispiel:
Beachten Sie, wie Donalds erstes „Ich kann nicht glauben, dass das passiert“mit Verzweiflung und Tränen geäußert werden sollte („seine Schultern zittern vor Schluchzen“), während sein späterer Dialog kalt und wütend klingen sollte („seine Augen glühen vor Wut“). Ohne den umgebenden Kontext könnte ein TTS-System beide Zeilen mit demselben emotionalen Ton erzeugen und so den dramatischen Bogen des Gesprächs verpassen.
Die KI von LyricWinter analysiert den emotionalen Kontext rund um jede Zeile, um den emotionalen Ausdruck des Stimmmodells zu steuern. Hier sehen Sie, welche Modelle die emotionale Steuerung unterstützen:
Models WITH Emotional Control:
- zyphra zonos-v0.1 [Veraltet][3]: Verwendet 8-dimensionale Emotionsgewichtungen, einschließlich Glück, Traurigkeit, Wut, Angst, Überraschung, Ekel, Neutralität und andere. Die KI analysiert den Kontext der Geschichte, um für jede Dialogzeile automatisch die entsprechenden Emotionsniveaus festzulegen. One-Shot-Stimmenklonen.
- gpt-4o-mini-tts[1]: Verwendet kontextbezogene Anweisungen basierend auf einer Story-Analyse. Das System untersucht den umgebenden Dialog und die Erzählung, um Anweisungen in natürlicher Sprache zu generieren, die die emotionale Vermittlung steuern. Trainingsbasiertes Klonen von Stimmen.
Models WITHOUT Emotional Control:
- tts-1+rvc[1][4]: Trainingsbasiertes Stimmenklonen
- fishaudio[2]: One-Shot-Stimmenklonen
- sparktts [Veraltet][8]: One-Shot-Stimmenklonen. Während die zugrunde liegende Technologie 24 Emotionskategorien unterstützt, verwendet die aktuelle Implementierung von LyricWinter keine kontextbezogene Emotionsanalyse.
Das heißt nicht, dass tts-1 oder fishaudio keineswegs schlecht sind, weil sie keine kontextabhängige emotionale Steuerung erhalten, sie sind großartig. Es müssen Kompromisse gemacht werden. Ich selbst bevorzuge tts-1 für den Erzähler wegen der Konsistenz der Trittfrequenz.
Fehlerbehandlung
Was tun, wenn das Sprachmodell ausfällt? Beispielsweise schneidet Zyphra zonos-v0.1 [veraltet] häufig Silben am Zeilenanfang oder -ende aus. Wir verwenden whisper[5], um das Audio zu transkribieren und zu überprüfen, ob die Generierung erfolgreich war. Wenn nicht, versuchen wir es ein paar Mal erneut. Sollte es weiterhin fehlschlagen, greifen wir auf ein anderes Sprachmodell zurück. Das ist der Kern: Versuchen Sie es erneut und greifen Sie bei Bedarf zurück.
Wiederholungsversuche verlangsamen die Arbeit, aber letztendlich wollen wir qualitativ hochwertige Ergebnisse. Normalerweise ist es nicht so schlimm. Obwohl Zonos [veraltet] ziemlich unzuverlässig ist. Ich habe tatsächlich ein Interview mit ihnen geführt – großes Lob an sie! Sie haben ein gutes Produkt gebaut, obwohl sie mich unbedingt hätten beauftragen sollen, die Dinge zuverlässig zu machen.
Und natürlich Fehlerverfolgung! Fehler werden zur Überprüfung protokolliert.
Geschwindigkeit
Einige dieser Modelle laufen auf externen Diensten, andere auf einer serverlosen Infrastruktur. Dennoch werden Anfragen nach Geschwindigkeit verteilt! Grüße an Modal[6]. Ursprünglich habe ich Runpod und Google Cloud Run verwendet, aber --- sie waren zu langsam. + Modal hat mir eine Menge Gratis-Credits gegeben. Ich liebe sie. Wenn jede Anfrage abgeschlossen ist, ruft der Client (Ihr Browser) die Audiodaten ab und verkettet sie. Sobald der erste Dialogclip fertig ist, können Sie mit dem Zuhören beginnen!
Zeit zum Zuhören!
Dein Audio ist bereit zum Anhören, und du kannst es optional als .wav herunterladen oder bei Bedarf die .srt-Datei downloaden.
Probieren Sie es selbst aus!
Der beste Weg, LyricWinter zu verstehen, besteht darin, es zu erleben. Gehen Sie zur Generate-Seite, fügen Sie Ihre Lieblings-Fanfiction, Light Novel oder Kurzgeschichte ein und beobachten Sie, wie die KI Ihre Lieblingscharaktere mit Immersion in den Audiobereich bringt. Mit SparkTTS [veraltet] verfügen wir über ein großzügiges, englischsprachiges kostenloses Kontingent, sodass Sie unverbindlich experimentieren können.
Egal, ob Sie ein Fanfiction-Autor sind, der seine Geschichten laut hören möchte, ein Light-Novel-Leser, der nach Erzählwerkzeugen sucht, oder einfach nur neugierig auf KI-Sprachtechnologie sind, LyricWinter bietet etwas Einzigartiges: die Möglichkeit, jeden Text mit nur wenigen Klicks in ein immersives Audioerlebnis mit unterschiedlichen Charakterstimmen zu verwandeln.
Viel Spaß beim Geschichtenerzählen! Und wenn Sie Fragen oder Feedback haben, können Sie sich gerne an uns wenden. Ich bin immer gespannt, wie die Leute LyricWinter nutzen und welche Funktionen sie als nächstes sehen möchten.
Notiz
Identitätswechsel oder betrügerische Nutzung ist nicht gestattet! Dies dient der Freizeitgestaltung und dem persönlichen Gebrauch. LyricWinter ist nicht mit den von Benutzern hochgeladenen Stimmen verbunden und beansprucht auch nicht das Eigentum daran. Wie in diesem Artikel hervorgehoben, ist LyricWinter ein eingabe- und sprachunabhängiges System. Die angegebenen Beispiele dienen nur zur Veranschaulichung.
References
- [1]OpenAI Platform - Text-to-Speech Guide
- [2]Fish Audio - Text-to-Speech Platform
- [3]Zyphra - Zonos v0.1
- [4]RVC-Project - Retrieval-based Voice Conversion WebUI
- [5]OpenAI Whisper - Automatic Speech Recognition
- [6]Modal - Serverless GPU Computing Platform
- [7]Groq - Fast AI Inference Platform
- [8]SparkAudio - Spark TTS