Come funziona LyricWinter: la tecnologia dietro le storie con voci AI
Un approfondimento su come funziona LyricWinter, dall'analisi della storia alla clonazione vocale AI. Scopri come trasformiamo fanfiction e light novel in esperienze audio immersive.
Pubblicato da
Letture correlate
Come funzionano le scorciatoie vocali in LyricWinter
Scopri come le scorciatoie vocali di LyricWinter salvano le assegnazioni dei personaggi, gestiscono gli alias e riutilizzano le anteprime di AI Voice tra più storie.
Importare storie da AO3 e FanFiction.net in LyricWinter
Importa storie da AO3 o FanFiction.net in LyricWinter, genera link condivisibili e trasforma fanfiction in audio con voci AI per più personaggi.
Come ascoltare fanfiction (gratis, veloce e con più voci)
Scopri i modi più semplici per ascoltare fanfiction: TTS rapido e gratuito, lettura ad alta voce del browser, podfic della community e l'opzione più immersiva: audio IA con più voci per i personaggi tramite LyricWinter. Configurazione passo passo inclusa.
Voglio mostrarti esattamente come LyricWinter trasforma le tue storie scritte in esperienze audio immersive con voci dei personaggi distinte. Quello che era nato come progetto secondario per alimentare il mio desiderio di ascoltare invece di leggere si è evoluto in un sistema AI sofisticato, capace di gestire centinaia di clip di dialogo in parallelo.
La sfida principale: narrazione espressiva a più personaggi con voci clonate
Il problema fondamentale che LyricWinter risolve è semplice da formulare ma complesso da eseguire: come si prende una storia scritta con più personaggi e si genera audio in cui ogni personaggio ha una propria voce coerente e di alta qualità?
Idealmente, vogliamo che il nostro sistema abbia tutte queste qualità:
- Multilingue
- Clonazione accurata
- Eccellenza nelle vocalizzazioni non lessicali
- Chiaro
- Espressivo
- Piacevole da ascoltare a lungo
- Stabile nelle narrazioni lunghe
- Supporto di più parlanti sovrapposti
- Controllabile
- Veloce
- Conveniente
Approfondiremo come ottenere tutte queste qualità in un altro articolo. Prima, capiamo come funziona LyricWinter.
Step 1: Understanding Your Story with AI
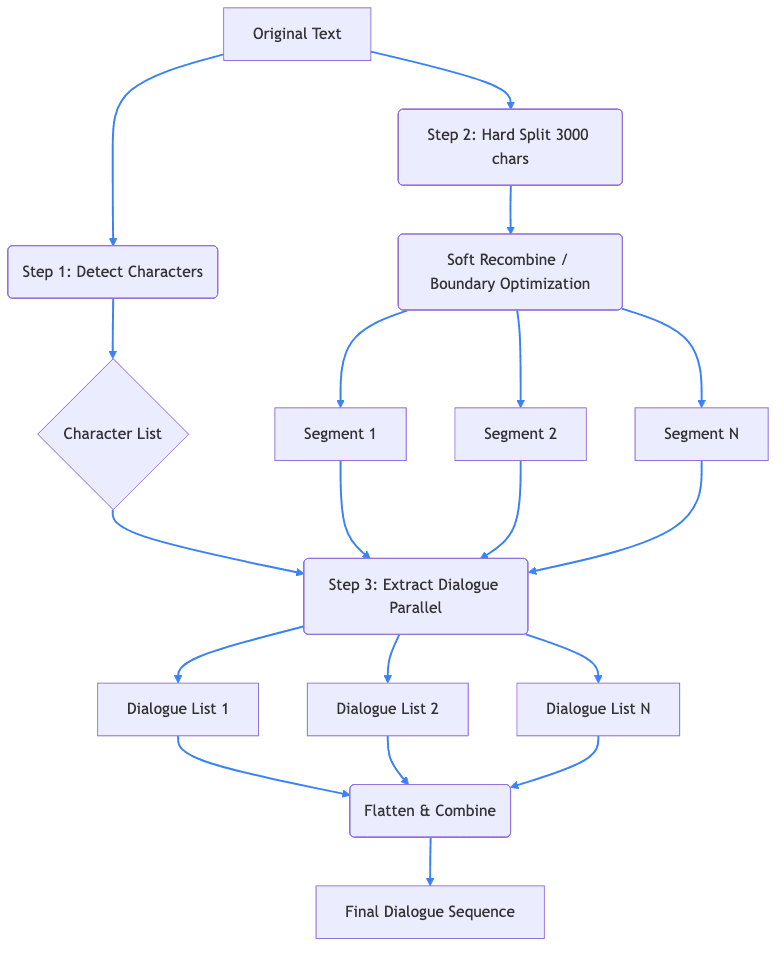
Figure 1: The recursive parsing and extraction pipeline
Quando incolli la tua storia in LyricWinter, la prima cosa che avviene è l'analisi della storia basata sull'AI.
Rilevamento dei personaggi
Il sistema usa l'AI per identificare ogni personaggio distinto nella tua storia. È abbastanza intelligente da riconoscere che "Harry", "Mr. Potter" e "The Boy Who Lived" si riferiscono tutti allo stesso personaggio.
Estrazione e attribuzione dei dialoghi
Poi arriva l'estrazione dei dialoghi. Per narrare, dobbiamo sapere che cosa sta dicendo ogni personaggio che parla. LyricWinter usa l'AI insieme all'elenco dei personaggi del passaggio precedente per estrarre i dialoghi.
È un passaggio piuttosto delicato, perché l'attribuzione dei dialoghi non è sempre ovvia. Considera questo esempio difficile che un utente ha inviato per il debug:
Anche gli esseri umani riescono a seguire abbastanza bene il flusso della conversazione, ma diverse battute non hanno indicazioni esplicite del parlante. Chi ha dato la risposta definita "immediate"? Chi ha detto "We won't"? Chi ha mormorato "So is doing nothing"?
Hermione e Ron sono i candidati più probabili a dire "Are you mad?", ma poiché più avanti Ron dice "What if we get caught?", possiamo attribuire a lui la battuta precedente. Quanto a "So is doing nothing," sappiamo che viene pronunciata da un personaggio indicato con "he", quindi potrebbe essere Ron o Harry, ma vista la determinazione di Harry possiamo attribuirla a lui.
L'AI di LyricWinter analizza gli schemi della conversazione, le personalità dei personaggi e gli indizi contestuali per suddividere correttamente il testo in singole clip di dialogo:
[
{
"text": "We need to get this to Dumbledore,",
"speaker": "Harry"
},
{
"text": "Harry said urgently.",
"speaker": "Narrator"
},
{
"text": "Are you mad?",
"speaker": "Ron"
},
{
"text": "The response was immediate.",
"speaker": "Narrator"
},
{
"text": "It's past midnight.",
"speaker": "Ron"
},
{
"text": "Ron glanced nervously at the corridor.",
"speaker": "Narrator"
},
{
"text": "What if we get caught?",
"speaker": "Ron"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "he followed.",
"speaker": "Narrator"
},
{
"text": "Hermione had been quiet up till now.",
"speaker": "Narrator"
},
{
"text": "This is incredibly dangerous.",
"speaker": "Hermione"
},
{
"text": "So is doing nothing,",
"speaker": "Harry"
},
{
"text": "he muttered.",
"speaker": "Narrator"
},
{
"text": "Fine,",
"speaker": "Hermione"
},
{
"text": "she muttered.",
"speaker": "Narrator"
},
{
"text": "But if we end up in detention...",
"speaker": "Hermione"
},
{
"text": "We won't,",
"speaker": "Harry"
},
{
"text": "Harry repeated, already moving toward the portrait hole.",
"speaker": "Narrator"
}
]Questo passaggio può richiedere 1-2 minuti, o di più per storie più lunghe. Ci sono ulteriori ottimizzazioni che potrebbero ridurlo a ~10 secondi, per esempio fare il fine-tuning di un LLM per questo compito e farlo girare su groq[7]. Man mano che LyricWinter diventerà più popolare, lavorerò per aggiungerlo.
A questo punto, ogni battuta associata al suo parlante è quasi pronta per essere narrata.
Assegnazione delle voci
Ok, sappiamo che Harry ha detto "We need to get this to Dumbledore," ma... chi è Harry? Harry è più di un semplice nome. Harry è un personaggio, con una personalità, una voce e un ruolo nella storia. Per narrare in modo immersivo, non possiamo semplicemente assegnare una voce casuale a Harry. Dobbiamo assegnargli una voce adatta alla sua personalità e al suo ruolo nella storia.
Ci sono due scenari:
- Un utente ha aggiunto una voce pubblica per "Harry Potter" in Le mie voci
- Nessuno ha aggiunto una voce per "Harry Potter"
Nel primo scenario, l'AI è abbastanza intelligente da associare la voce "Harry Potter" al personaggio "Harry" nella storia.
Nel secondo scenario, l'AI usa il nome, la descrizione e i tag di ogni voce pubblica per assegnare a "Harry" la voce più appropriata. Per esempio, sceglierà una voce maschile con accento britannico, se disponibile.
E naturalmente le voci impostate come private sono disponibili solo per te.
Ecco cosa ha suggerito l'AI per il nostro esempio di Harry Potter:
{
"suggested_character_voices": {
"Ron": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "b4cddece-a29d-4652-94cf-1c0d80b4f380",
"voice_name": "Draco Malfoy"
},
"Harry": {
"model": "fishaudio",
"voice_id": "b03285ef-ade9-4785-aff1-ec07accc1735",
"voice_name": "Harry Potter"
},
"Hermione": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "1f9b9aef-41af-455c-822d-5dd0b4cc257e",
"voice_name": "Alice (Alice in Wonderland)"
},
"Narrator": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "5591864d-cfaf-490e-88e5-586e956847c3",
"voice_name": "Narrator"
},
"Dumbledore": {
"model": "gpt-4o-mini-tts+rvc",
"voice_id": "76370ff9-1de1-48ab-9d64-a5b345584d1b",
"voice_name": "Zhongli"
}
}
}Nota come l'AI abbia trovato una voce corrispondente a "Harry Potter", ma abbia assegnato in modo creativo "Draco Malfoy" a Ron e "Alice" a Hermione in base alle caratteristiche della voce e alla disponibilità. Persino Dumbledore viene abbinato a "Zhongli": una voce saggia e autorevole adatta al personaggio. Questo perché nessun utente ha caricato una voce per Ron/Hermione/Dumbledore.
Nota anche gli ID voce: possono esistere più voci con lo stesso nome, quindi gli ID voce vengono usati per identificare in modo univoco una voce durante l'assegnazione.
Inoltre, puoi vedere i modelli suggeriti per ogni voce. Diversi laboratori di AI rilasciano modelli diversi per la clonazione vocale e la sintesi vocale, e questi modelli hanno prestazioni diverse a seconda della voce. Al momento l'AI non è molto brava a suggerire i modelli, quindi prima di generare l'audio hai la possibilità di modificare i suggerimenti dell'AI, sia il modello vocale sia la voce stessa.
Ecco una panoramica dei modelli vocali disponibili in LyricWinter e delle loro caratteristiche:
| Modello | Qualità | Fedeltà al personaggio | Affidabilità | Emozione |
|---|---|---|---|---|
fishaudio | ||||
sparktts [DEPRECATO] | ||||
zyphra [DEPRECATO] |
Come puoi vedere, ogni modello ha punti di forza diversi. gpt-4o-mini-tts+rvc eccelle nell'emozione e nella fedeltà al personaggio, mentre tts-1+rvc offre la qualità e l'affidabilità migliori. L'AI cerca di abbinare il modello migliore a ogni voce, ma nel processo di generazione l'ultima parola è tua.
🌍 Supporto multilingue per modello
Inglese, cinese, giapponese, tedesco, francese, spagnolo, coreano, arabo, russo, olandese, italiano, polacco, portoghese
Inglese, francese, tedesco, giapponese, coreano, cinese mandarino
Inglese, cinese
Nota: fishaudio offre un ampio supporto linguistico, ideale per contenuti internazionali e narrazione multilingue.
Passaggio 2: narrare la tua storia con l'AI
Ora che abbiamo i dialoghi e le voci selezionate, possiamo iniziare a narrare la storia.
Narrazione
Quando fai clic su Genera audio, ogni combinazione di parlante, battuta, testo, voce e modello vocale viene inviata al modello vocale specificato per essere sintetizzata. Tuttavia, questo non basta. Il contesto è essenziale per una sintesi vocale emotivamente coinvolgente. Prendi questo esempio:
Nota come il primo "I can't believe this is happening" di Donald dovrebbe essere pronunciato con tono devastato e in lacrime ("his shoulders shaking with sobs"), mentre la battuta successiva dovrebbe suonare fredda e arrabbiata ("his eyes blazing with anger"). Senza il contesto circostante, un sistema TTS potrebbe generare entrambe le battute con lo stesso tono emotivo, perdendo l'arco drammatico della conversazione.
L'AI di LyricWinter analizza il contesto emotivo intorno a ogni battuta per guidare l'espressione emotiva del modello vocale. Ecco quali modelli supportano il controllo emotivo:
Models WITH Emotional Control:
- zyphra zonos-v0.1 [Deprecato][3]: usa pesi emotivi a 8 dimensioni, tra cui felicità, tristezza, rabbia, paura, sorpresa, disgusto, neutro e altro. L'AI analizza il contesto della storia per impostare automaticamente livelli emotivi appropriati per ogni battuta di dialogo. Clonazione vocale one-shot.
- gpt-4o-mini-tts[1]: usa istruzioni contestuali basate sull'analisi della storia. Il sistema esamina i dialoghi e la narrazione circostanti per generare istruzioni in linguaggio naturale che guidano la resa emotiva. Clonazione vocale basata sull'addestramento.
Models WITHOUT Emotional Control:
- tts-1+rvc[1][4]: clonazione vocale basata sull'addestramento
- fishaudio[2]: clonazione vocale one-shot
- sparktts [Deprecato][8]: clonazione vocale one-shot. Anche se la tecnologia sottostante supporta 24 categorie emotive, l'implementazione attuale di LyricWinter non usa l'analisi emotiva contestuale.
Questo non vuol dire che tts-1 o fishaudio siano scadenti solo perché non hanno un controllo emotivo dipendente dal contesto: sono ottimi. Ci sono compromessi da fare. Io stesso preferisco tts-1 per il Narratore, per la costanza della cadenza.
Gestione degli errori
Che cosa fai quando il modello vocale sbaglia? Zyphra zonos-v0.1 [Deprecato], per esempio, spesso taglia sillabe vicino all'inizio o alla fine della battuta. Usiamo whisper[5] per trascrivere l'audio e controllare se la generazione è riuscita. Se non lo è, riproviamo alcune volte. Se continua a fallire, passiamo a un altro modello vocale. Il principio di base è questo: riprovare e usare un fallback quando serve.
I tentativi ripetuti rallentano tutto, ma alla fine vogliamo risultati di alta qualità. Di solito non va troppo male. Però zonos [Deprecato] è piuttosto inaffidabile. Ho persino fatto un colloquio con loro -- un saluto a loro! Hanno costruito un buon prodotto, anche se avrebbero proprio dovuto assumermi per renderlo affidabile.
E naturalmente c'è anche il tracciamento degli errori! Gli errori vengono registrati per essere esaminati.
Velocità
Alcuni di questi modelli girano su servizi esterni, altri su infrastruttura serverless. In ogni caso, le richieste vengono distribuite per aumentare la velocità! Un saluto a Modal[6]. All'inizio usavo Runpod e Google Cloud Run, ma --- erano troppo lenti. In più Modal mi ha dato un bel po' di crediti gratuiti. Li adoro. Quando ogni richiesta viene completata, il client (il tuo browser) recupera l'audio e lo concatena. Appena la prima clip di dialogo è completa, puoi iniziare ad ascoltare!
È ora di ascoltare!
Il tuo audio è pronto per l'ascolto e, se vuoi, puoi scaricarlo come file .wav o scaricare il file .srt.
Provalo tu stesso!
Il modo migliore per capire LyricWinter è provarlo. Vai alla pagina Genera, incolla la tua fanfiction, light novel o racconto preferito e guarda l'AI dare voce ai tuoi personaggi preferiti in un'esperienza audio immersiva. Abbiamo un generoso piano gratuito per contenuti in inglese con SparkTTS [Deprecato], quindi puoi sperimentare senza alcun impegno.
Che tu sia uno scrittore di fanfiction che vuole ascoltare le proprie storie ad alta voce, un lettore di light novel in cerca di strumenti di narrazione, o semplicemente curioso della tecnologia vocale AI, LyricWinter offre qualcosa di unico: la capacità di trasformare qualsiasi testo in un'esperienza audio immersiva con voci dei personaggi distinte, il tutto in pochi clic.
Buona narrazione! E se hai domande o feedback, contattami pure. Sono sempre felice di sapere come le persone usano LyricWinter e quali funzionalità vorrebbero vedere in futuro.
Nota
Non è consentito impersonare altri né usare il servizio a fini dannosi! Questo strumento è pensato per svago e uso personale. LyricWinter non è affiliato ad alcuna delle voci caricate dagli utenti, né ne rivendica la proprietà. Come evidenziato in questo articolo, LyricWinter è un sistema indipendente dall'input e dalle voci. Gli esempi forniti sono solo a scopo illustrativo.
References
- [1]OpenAI Platform - Text-to-Speech Guide
- [2]Fish Audio - Text-to-Speech Platform
- [3]Zyphra - Zonos v0.1
- [4]RVC-Project - Retrieval-based Voice Conversion WebUI
- [5]OpenAI Whisper - Automatic Speech Recognition
- [6]Modal - Serverless GPU Computing Platform
- [7]Groq - Fast AI Inference Platform
- [8]SparkAudio - Spark TTS